 PoBot
PoBot
 La localisation des sources de son
La localisation des sources de sonCet article a fait l’objet d’une suite avec un portage en C++ sous Linux avec le son ALSA.
Le principe
Le principe est assez simple :
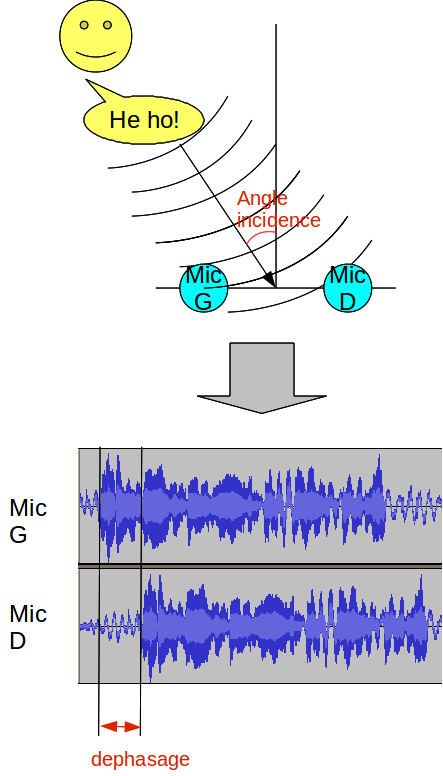
– on écoute le son avec deux microphones séparés de quelques centimètres (les deux "oreilles")
– suivant la direction d’un son incident, l’un des deux microphones recevra le signal légèrement avant l’autre car il est plus près de la source. A part ce léger décalage, les signaux reçus par chaque micros sont les mêmes.
– en mesurant cette différence de temps (Interaural Time Difference (ITD) pour les intimes), on peut en déduire l’angle d’incidence du son
Un petit schéma :
Bien sur, il y a tout plein de références théoriques la dessus. Si vous voulez creuser, vous pouvez partir de l’article de Wikipedia (en anglais) Sound Localization.
A noter qu’une autre façon de détecter la direction du son est la différence de puissance entre les deux cotés (Interaural Level Difference (ILD ou IID) pour les intimes) : est ce que c’est plus fort à droite qu’à gauche ?
C’est une méthode facile à mettre en œuvre, mais qui est moins robuste et précise que celle présentée ici.
Le grand avantage de la différence de temps interaurale est en effet sa grande robustesse : elle fonctionne bien quel que soit le type de son, et quelles que soient les variations d’intensité du son.
En particulier, ça marche pour les sons courts comme pour les sons longs ou continus tels que la parole. Magique 🙂
Le Matériel
Pour valider le principe, on va faire simple :
– un PC avec une carte son
– un micro stéréo formé de deux micros placés à quelques centimètres (10-20) l’un de l’autre
On n’a pas toujours un PC dans son robot, mais de plus en plus...un netbook ne coûte pas trop cher et ne pèse pas grand chose.
Pour le micro stéréo, il y a plusieurs possibilités :
– beaucoup de netbooks modernes sont déjà équipés comme cela par défaut pour améliorer la vidéo conférence : deux micros séparés de quelques centimètres permettent en effet d’écouter dans une direction privilégiée en supprimant les bruits latéraux, grâce à un peu de traitement du signal. Bref : si votre netbook a deux petits trous sous l’écran, séparés de quelques centimètres, c’est gagné 🙂
– on peut acheter un micro stéréo de ce genre tout fait, par exemple le SuperBeam d’AndreaElectronics : c’est celui que j’ai utilisé pour mes expérimentations. Ça se trouve sur eBay pour pas trop cher, par exemple la
– on peut le faire custom, en soudant deux micros electret sur une jack stéréo standard : j’en ai fait un aussi comme ça avec deux micros achetés en solderie 1,5 euros, mais il a fini par se dessouder, pffff...
Le Logiciel
Le logiciel est écrit en Java, parce que 🙂. Bien entendu c’est facilement adaptable à d’autres langages.
Pour traiter le son, il faut d’abord l’obtenir. Pour cela, on utilise l’API Java Sound qui fait partie des JDKs standards.
On échantillonne l’entrée micro à 44 KHz, 16 bits, deux canaux (droite et gauche) :
AudioFormat samplingFormat = new AudioFormat(44100, 16, 2, true, false) ;
TargetDataLine inputMic = AudioSystem.getTargetDataLine(samplingFormat) ;
inputMic.open() ;
inputMic.start() ;
if (!inputMic.isActive())
throw new Exception("input mic not ready, audio issue ?") ;
AudioInputStream rawIn = new AudioInputStream(inputMic) ;
L’API Java Sound nous donne un stream dont il faut ensuite décoder les octets suivant le format pour en tirer ce qui nous intéresse, les échantillons.
En fouillant un peu, j’ai trouvé des classes de la librairie Java open source Tritonus qui font ça très bien pour nous, donc inutile de réinventer la roue : la classe org.tritonus.share.sampled.FloatSampleBuffer nous fournira directement un tableau, rempli avec le nombre d’échantillons demandés :
_inputStream = new FloatInputStream(rawIn) ;
_buffer = new FloatSampleBuffer(2, _bufferSize, _inputStream.getSampleRate()) ;
Et maintenant c’est parti, on boucle à l’infini et on traite un bloc de son à chaque itération (un bloc = un buffer = 4096 échantillons = un peu moins d’une seconde de son) :
public void run()
while (!_inputStream.isDone())
processNextSoundBlock() ;
private void processNextSoundBlock()
_inputStream.read(_buffer) ;
Le traitement implémente le principe exposé plus haut.
L’objectif est de trouver le décalage entre les canaux droits et gauches, en supposant qu’ils reçoivent le même son légèrement décalé dans le temps.
Pour ce faire, on va garder le canal droit original, et décaler le son du canal gauche progressivement.
Pour chaque décalage, on va mesurer la ressemblance entre les deux signaux : le décalage pour lequel ils sont le plus ressemblants est celui que l’on cherche ! En effet, si les deux canaux reçoivent le même son simplement décalé, lorsque l’on trouve le ’bon’ décalage ils sont identiques (i.e. très ressemblants).
En traitement du signal, la ressemblance de deux signaux s’appelle l’intercorrélation. C’est un gros mot, mais il suffit de retenir que c’est une mesure de la ressemblance. Bien sur, il y a tout un fatras mathématique autour, mais je vous en dispense 🙂
L’intercorrélation est un calcul assez lourd, mais dans notre cas on peut le simplifier : on ne veut pas vraiment la calculer, mais simplement trouver son maximum. Un peu de math permet de prouver que le maximum de l’intercorrélation est aussi le minimum de la somme des valeurs absolues des différences des deux signaux à chaque instant (ouf !).
L’avantage c’est que c’est un calcul assez simple, sans multiplication, donc peu consommateur de CPU.
En pratique on a donc :
– on fait varier un décalage ’t’ entre -décalage_max et +décalage_max
– pour chaque valeur de ’t’, on calcule la somme des différences des canaux à chaque instant, le canal gauche étant décalé de ’t’.
– on garde le décalage pour laquelle la somme est minimale
Ça donne çà :
float minDiff = Float.MAX_VALUE;
int minDiffTime = -1;
float[] right = _buffer.getChannel(0);
float[] left = _buffer.getChannel(1);
for (int t = -_nbSamplesMaxDiff; t < _nbSamplesMaxDiff; t++) {
float diff = 0;
for (int i = _nbSamplesMaxDiff; i < left.length - _nbSamplesMaxDiff - 1; i++) {
diff += Math.abs(left[i] - right[i + t]);
}
if (diff < minDiff) {
minDiff = diff;
minDiffTime = t;
}
}Une bonne chose de faite, on connait maintenant le décalage.
Il reste un soucis : en pratique, on ne veut alerter le robot d’un son que si il est significatif, c’est à dire ’suffisamment’ fort. En effet, il y a toujours un bruit de fond autour du robot, et on ne veut pas osciller continuellement autour du bruit de fond, de direction plus ou moins aléatoire.
On va donc calculer la puissance du son, et ne réagir que pour les sons significatifs, c’est à dire au dessus du bruit de fond.
Afin d’éviter de coder ’en dur’ la puissance du bruit de fond, qui dépend de l’environnement, on va calculer la moyenne glissante du bruit entendu en permanence, et définir ’significatif’ comme étant 5% au dessus de ce bruit moyen. Cela permet une calibration automatique pour s’adapter au bruit ambiant.
On en profite pour éliminer les mesures de décalage extrême, qui sont souvent signe de mauvaise mesure, et ça donne ça :
float level = computeLevel(right, left);
_averageSoundLevel.newValue(level);
float relativeLevel = level / _averageSoundLevel.getMean();
if ((relativeLevel > _minLevelFactorForValidLoc)
&& (minDiffTime > -_nbSamplesMaxDiff)
&& (minDiffTime < _nbSamplesMaxDiff)) {
<son significatif, on réagit>
}Avec un peu de code pour calculer la puissance du son et la moyenne glissante :
private float computeLevel(float[] right, float[] left) {
float level = 0;
for (int i = 0; i < right.length; i++) {
float s = (left[i] + right[i]) / 2;
level += (s * s);
}
level /= right.length;
level = (float) Math.sqrt(level);
return level;
}
static public class RunningAverage {
private final int _nbValuesForAverage;
private int _nbValues;
private float _mean;
RunningAverage(int nbValuesForAverage) {
_nbValuesForAverage = nbValuesForAverage;
}
public void newValue(float v) {
if (_nbValues < _nbValuesForAverage)
_nbValues++;
_mean = ((_mean * (_nbValues - 1)) + v) / _nbValues;
}
public float getMean() {
return _mean;
}
}Ouf ! On a le décalage et la puissance, il ne manque plus qu’à en déduire l’angle d’incidence et à réagir.
Pour calculer l’angle, on va supposer une relation linéaire entre le décalage de phase et l’angle d’incidence. En fait, ce n’est pas tout à fait exact mais c’est une assez bonne approximation, en tout cas suffisante pour notre usage. On peut trouver sur le net un tas de formules sur le front d’onde, donc on peut sans doute faire mieux avec un peu de trigo...
Mais comme je suis un peu feignant, j’ai juste mesuré la valeur maximum de décalage de temps que j’obtenais avec l’angle maximum (90 degrés par rapport aux micros), et fait une interpolation linéaire. Pas de calcul théorique sur la vitesse du son, l’écartement des micros, les angles, la fréquence échantillonnage... feignant quoi 🙂
Ça donne ça :
float angle = -(float) (Math.PI / 2 * ((float) minDiffTime / _nbSamplesMaxDiff));On arrive au bout de nos peines, il ne reste plus qu’à mettre un peu de peinture autour de tout ça pour représenter le résultat et faire des essais.
Pour cela, quelques lignes de swing pour représenter l’angle sur un demi cercle, avec la largeur de la ligne dépendant de la puissance du son (grosse ligne = son fort) :
static private class SoundLocDraw extends JPanel {
// sound angle, between -PI/2...+PI/2
private float _angle;
// relative power with respect to mean power (1.0=mean power)
private float _relativePower;
public void setSound(float angle, float relativePower) {
_angle = angle;
_relativePower = relativePower;
repaint();
}
@Override
protected void paintComponent(Graphics g) {
super.paintComponent(g);
Graphics2D g2d = (Graphics2D) g;
Dimension d = getSize();
int radius = Math.min(d.height, d.width / 2);
int cx = d.width / 2;
int cy = 0;
int tx = cx + (int) (Math.cos(_angle + Math.PI / 2) * radius);
int ty = cy + (int) (Math.sin(_angle + Math.PI / 2) * radius);
g2d.drawOval(cx - radius, cy - radius, radius * 2, radius * 2);
// use larger strokes for louder sounds:
g2d.setStroke(new BasicStroke(1 + (int) ((Math.max(_relativePower,
1) - 1.0) * 10)));
g2d.drawLine(cx, cy, tx, ty);
}
}Le tout est rassemblé dans la classe soundsourceloc.SoundSourceLoc, que vous trouverez avec l’ensemble du code source dans l’archive jointe à cet article.
Résultats
En pratique, ça marche plutôt bien !
Je n’ai pas fait de mesure de précision, mais en jouant un peu avec le prototype la localisation du son semble fiable, même en présence de bruits de fond parasites.
Il y a peu de ’fausses’ détections, et l’ensemble devrait pouvoir remplir la fonction envisagée, tourner la tête en direction du son.
On appelle le ’robot’ pas trop fort à son extrême droite :
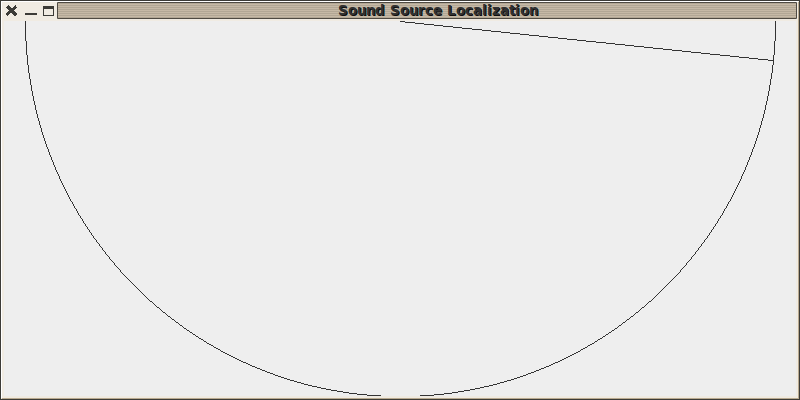
Puis un peu plus fort au milieu à gauche :
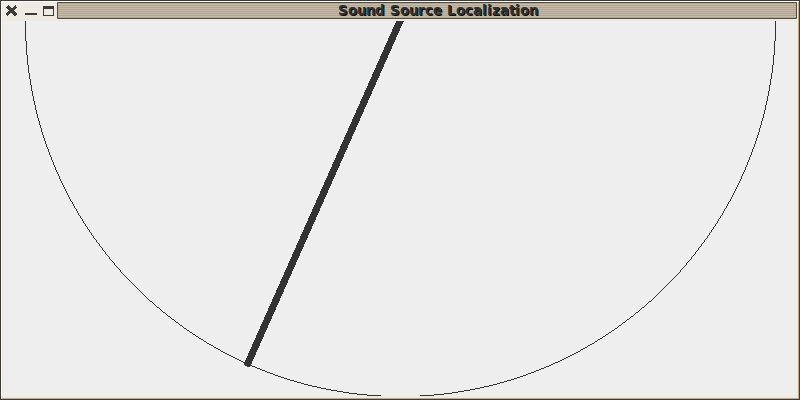
Voila !
Il ne reste plus qu’à mettre ça en place sur un vrai robot, et tester en conditions réelles... probablement l’objet d’un prochain article 🙂





Vos commentaires
# Le 12 septembre 2010 à 21:12, par Mathieu S. En réponse à : La localisation des sources de son
En réponse à : La localisation des sources de son
J’ai réalisé cette année un petit projet sur ce sujet. En gros j’avais une caméra pan-tilt qui devait regarder en direction de la personne qui parle.
Donc j’ai déjà calcul de l’angle en fonction de la différence de temps entre les micros :
float angle = asin((minDiffTime*Vson)/(fe*distMicro)) ;
Avec minDiffTime le nombre d’echantillon décalée que tu calcules avec le normalised cross correlation.
Vson = la vitesse du son en m/s (=343,4m/s à 20°C)
fe = frequence d’echantillonage de ton signal audio (=44100hz dans ton exemple)
distMicro = la distance entre tes micros en mètres.
Cette formule est encore une approximation de la réalité, mais est déjà plus précise qu’une interpolation linéaire ;)
# Le 13 septembre 2010 à 14:42, par Frédéric P. En réponse à : La localisation des sources de son
En réponse à : La localisation des sources de son
Génial, merci !
Je savais bien qu’une bonne âme (courageuse, elle 🙂 ) passerait par là.
Sur la caméra qui regarde la personne qui parle : je voudrais aller aussi dans cette direction. En fait j’ai fait quelques essais il y a un moment avec localisation du son, puis détection et tracking de visage (avec OpenCV), mais ca marchait assez moyen a vrai dire... Tu as fais des choses la dessus ?
# Le 17 août 2012 à 14:27, par stephane En réponse à : La localisation des sources de son
En réponse à : La localisation des sources de son
Bonjour,
je me présente, Stéphane, j’ai découvert votre site récemment et je le trouve très intéressant.
J’ai une formation en télécommunication et réseaux informatiques donc je connais un peu la programmation et l’électronique. J’ai acquis récemment un arduino duemilanove et une carte raspberry pi et je voulais me lancer dans la robotique dans mes temps libre.
Voilà pour les présentations, je post ici une petite question théorique :
Si le mécanisme décrit dans l’article ci-dessus peut servir de base pour orienter une webcam de la droite vers la gauche et/ou du haut vers le bas, il y a nécessairement un moteur, servo ou autre, par conséquent est-ce que la localisation de la source de son ne risque pas d’être perturbée par le bruit du moteur qui oriente la caméra ?
J’ai bien une solution (théorique toujours) mais qui me plait moyennement à savoir, une phase d’écoute puis après localisation du bruit, je coupe l’écoute et je pilote les moteurs puis j’écoute de nouveau... Ce qui me parait beaucoup moins efficace...
Est-ce que vous avez un retour d’expérience pratique sur le sujet ?
Merci.
A bientôt
# Le 17 août 2012 à 16:06, par Julien H. En réponse à : La localisation des sources de son
En réponse à : La localisation des sources de son
Bonjour Stéphane ! Tu as 100% raison : les moteurs font du bruit, donc il faut veiller à isoler les moteurs des micros. Ta solution n’est pas du tout inefficace, car il est tout à fait capable d’alterner détection et mouvement un nombre de fois suffisamment grand par seconde pour qu’un humain ne s’en rende pas compte.
Répondre à ce message
# Le 13 septembre 2010 à 17:24, par Mathieu S. En réponse à : La localisation des sources de son
En réponse à : La localisation des sources de son
Pour l’instant je n’ai fait qu’un prototype qui pointe la direction de l’utilisateur. Je dois aussi avoir des courbes de précision VS écart entre les micros qui doivent trainer quelque part xD
J’avais l’intention au départ de faire aussi du tracking de visage mais je n’ai pas eu le temps de développer l’idée. Si tu veux on peut tenter de dvp ca.
En ce moment je bosse à fond sur de la stéréo vision et la réalité augmentée. Par contre une idée d’amélioration serait dans un premier temps d’utiliser un 3ème micro qui ne soit pas dans l’axe des deux autres afin de pouvoir trianguler dans l’espace d’où vient la source sonore afin d’être sur que la caméra pointe vers un visage et pas vers des pieds :p
Répondre à ce message